When to use Replicated Volume Solutions
Author: Quinn Bast
Date: 1/12/2024, 10:12:00 AM
KubernetesPersistent VolumesHigh Availability
# When to use Replicated Volume Solutions
“High Availability” is the ability for your application to always be online and provide service. However, High Availability comes with a number of different attributes which allow it to happen. In order for a system to be highly available, it needs to be able to tolerate a number of common failure cases.
| Problem | Solution | Details |
|---|---|---|
| Outages or Node Failures | Redundancy | If one server goes offline, having a “standby” ready to take action allows mitigating any potential downtime. |
| High Throughput | Scalability | Servers need to be able to keep up with high input rates or they slow to a halt. Scalability allows your app to share incoming requests, allowing more traffic to be handled. |
| Disk Failure | Data Replication | When required files become inaccessible to a software, the software cannot function. Data replication ensures your data is stored in multiple locations and if one is inaccessible, other backups exist. |
# How do I make software Highly Available?
There are two main ways to ‘distribute’ your software to ensure that it is highly available.
- Software Replication
- Disk Replication
# Software Replication
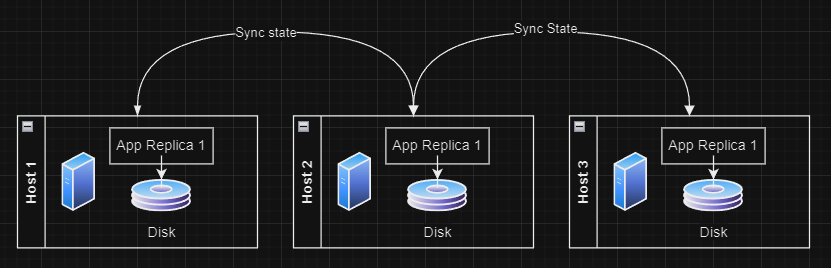
Microservices are generally created with scalability and clustering in mind.By utilizing the RAFT consensus algorithm, applications are able to share their internal state with each running instance of the application. By replicating state, if one (or more) instance of the software were to fail, the other instances would still be able to operate.
In this type of software, the software typically forms a ‘cluster', generally using RAFT protocol, to elect a leader of the cluster. Upon receiving data, each software replica will write the state to a local disk. Because the disk is local, the read/write access is extremely fast and the data replication is managed within the software’s leader-election itself.
To implement this in your own software, you would probably use a RAFT client library while persisting a WAL (write-ahead log) to persiste the state of each replica. A number of different ones are listed here (opens new window). Even though the software is using local disks here, if one were to fail, the software would be able to tolerate the failure because the software is “clustered”. Once the failing system comes back online, it can ask the cluster “what did I miss?” and get caught right back up. Thus, if a software system supports clustering, we can use local disks.
TIP
In Kubernetes, it is important that any “clustered” software should ALWAYS use local-pv or hostpath volume providers. Local volumes are significantly faster, and because state is already being replicated between the software, no disk replication is required. In these systems, the software cluster already takes care of replication for you!
# Disk Replication
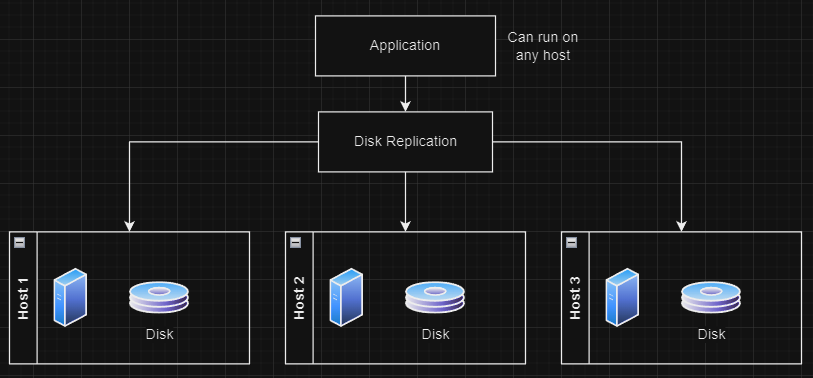
Certain apps were not created during the boom of micro-services. As such, some applications are not capable of being scaled or clustered with multiple software replicas. In order to allow these applications to still be highly available, disk replication can be used to provide the single application instance with access to it's data in multiple locations. This allows the single application the ability to be hardware agnostic and not be bound to a specific host, as the data exists in an available way behind the scenes.
In this scenario, an application can run with just a single running instance of the software. Behind the scenes, a third party storage system (or an in-house replication process) is able to duplicate/synchronise the filesystem to another host. This is done to ensure that there is a backup server with all of the relevant data incase the primary system has a disk failure. In the case of a disk failure, your app has it's data replicated so that it can still be brought back up on a different host.
At the lowest level, this type of replication is generally done through the use of Network Attached Storage (opens new window) or iSCSI (opens new window) protocols. However, because these protocols are such low-level, you often find the use of 3rd party libraries are used to support the replication features that these protocols don't provide. For example, Amazon's EFS (opens new window), Rook (opens new window), Longhorn (opens new window), OpenEBS (opens new window), and more. The image below shows how a single application can make use of the CSI layer through a 3rd party provider to replicate your data to different disks.
TIP
In the Kubernetes, the Container Storage Interface (opens new window) (CSI) layer allows applications to access and provide a filesystem to containers through a network mounted file-system (NAS or iSCSI, for example).
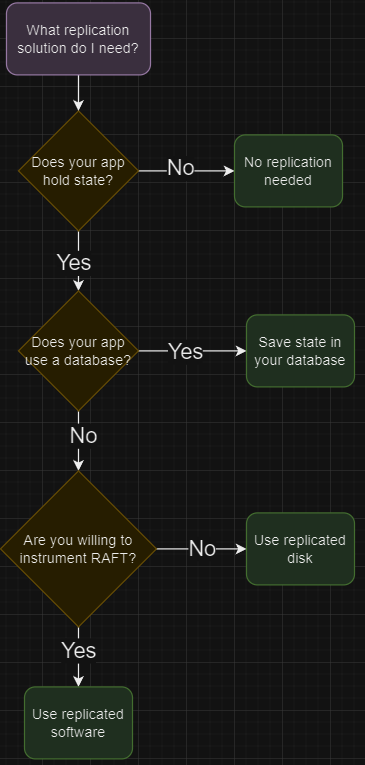
# Which do I need?
If you have to ask, it's probably a Replicated disk solution. But, not always.
If your software is highly available and can replicate & sync data among replicas with ease, then you would know that your application is highly available. If your software cannot do that, we need to ask some questions.
# CSI Drivers
For those using Kubernetes, using supported CSI drivers allow us to interface with Kubernetes Persistent Volumes and enable dynamic provisioning of volumes. Most CSI providers offer data replication out of the box. When looking at CSI drivers, there are two types of drivers:
# Local Volume Providers
Local volume providers like local-pv-provisioner (opens new window) or DirectPv (opens new window) are drivers that store a container's filesystem to a single host. Therefore, any workloads using the volume will be required to be scheduled to a particular node. These storage drivers do not replicate data between disks, and are therefore only useful for systems using Software Replication (as I explained above). Some examples include Kafka, MongoDB, or ElasticSearch, which are applications that provide their own high availability configurations.
# Replicated Volumes
Replicated Volumes are able to create a persistent volume which provides data replication and can make an otherwise non-HA application into an application that has data availability to support tolerating node or disk failures through data replication. These drivers will write to the CSI driver engines which will then synchronously write the required data to the number of desired replica disks. This type of storage is slower to access due to the requirement to replicate data across a number of disks, however, it ensures that your application can be highly available if there is no other option.
Some potential solutions include:
- OpenEBS (opens new window), a pluggable platform that supports container attached storage (CAS). OpenEBS can turn any storage system available to a k8s cluster into a local or distributed Persistent Volume – supporting both forms of disk availability with no vendor lock-in.
- Longhorn (opens new window), a beginner-friendly rancher-based volume solution which allows dynamically provisioned disks with both Local and Replicated voumes. It allows for users to take snapshots and backups to roll-back systems.
- Rook (opens new window), manages the deployment of a ceph storage cluster. Rook/Ceph provides disk replication to give disk availability to a cluster.
- NAS, a raw network attached storage device. While this is not highly available, the disks in the NAS could be configured for RAID to replicate data and avoid disk failures while providing a filesystem in a highly available way.